
音乐和音频是人类文化和艺术的重要组成部分,也是各种媒体和应用中不可或缺的元素。但是,创作音乐和音频并不是一件容易的事情,需要专业的技能、设备和时间。有没有一种方法,可以让我们只用文本就能生成高质量、逼真的音乐和音频呢?答案是有的,那就是 Meta 公司开源的 AudioCraft 工具。本文将介绍这款人工智能工具的原理、特点和应用场景。
Facebook 母公司 Meta 宣布开源文本生成音乐工具 Audiocraft,该工具可以帮助用户根据文本提示创作音乐和音频。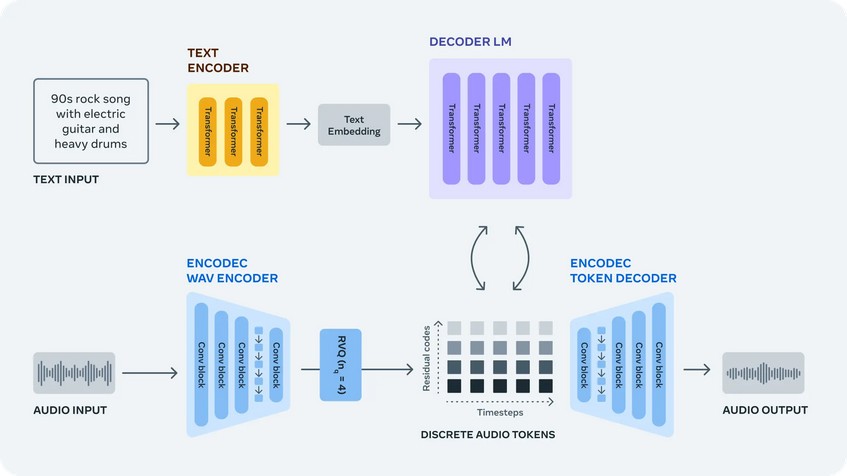
Meta 表示,这款人工智能工具将 AudioGen、EnCodec 和 MusicGen 三种模型或技术融为一炉,可用文本内容生成高质量、逼真的音频和音乐。比如用文本就能生成鸟叫、汽车喇叭声、脚步等背景音频,或更复杂的音乐,适用于游戏开发、社交、视频配音等业务场景。
根据官网的介绍,MusicGen 接受过 Meta 拥有的和特别授权的音乐训练,可以从文本提示生成音乐,而 AudioGen 接受过公共音效训练,可从文本提示生成音频,比如模拟狗叫或脚步声;再加上 EnCodec 编解码器的改进版本,用户可以更高效率地生成更高质量的音乐。
总结就是,Audiocraft 由 MusicGen、AudioGen 和 EnCodec 三个模型组合而成:
MusicGen 是一个文本生成音乐的自回归语言模型,大约使用了 40 万份文本描述和元数据的录音,总计 2 万小时的授权音乐进行训练。可通过文本自动生成摇滚、流行、重金属、RPA 等类型音乐。
AudioGen 是一个文本生成音频的自回归语言模型,具备分离音频功能,例如,可识别背景声、说话声和物体发出的声音等。这有助于仅使用文本生成音频时,更准确贴近用户的目标音乐。
EnCodec 是一个高保真音频、音乐的压缩和解压器,可以用最小的体积尽可能还原原始音乐,这对于打造高质量音频模型来说至关重要。EnCodec 由编码器、量化器和解码器三大块组成。
编码器,通过获取未压缩的数据,并将其转换为更高维度和更低帧速率的表示。
量化器,将编码器生成的 “表示” 压缩到目标大小,同时保留最重要的信息来重建原始信号。
解码器,将压缩信号转换回,与原始信号尽可能相似的波形。因为在低比特率下不可能进行完美的重建,所以,使用了鉴别器来提高音频生成样本的质量。
Audiocraft 是 Meta 公司开源的一款文本生成音乐和音频的工具,它结合了 AudioGen、EnCodec 和 MusicGen 三种模型或技术,可以根据文本提示生成各种类型和风格的音乐和音频,比如鸟叫、汽车喇叭声、脚步声等背景音效,或者摇滚、流行、重金属等音乐。Audiocraft 的优势在于它可以高效地压缩和解压音频数据,保证了音质的还原度,同时也提供了分离音频的功能,可以更准确地匹配用户的目标音乐。Audiocraft 适用于游戏开发、社交、视频配音等业务场景,可以帮助用户快速、简单地创作出富有表现力的音乐和音频。