
联发科天玑9300评测已出:全大核猛如虎!GPU/AI双惊喜,更耗电的全大核,怎么反而更省电了呢?
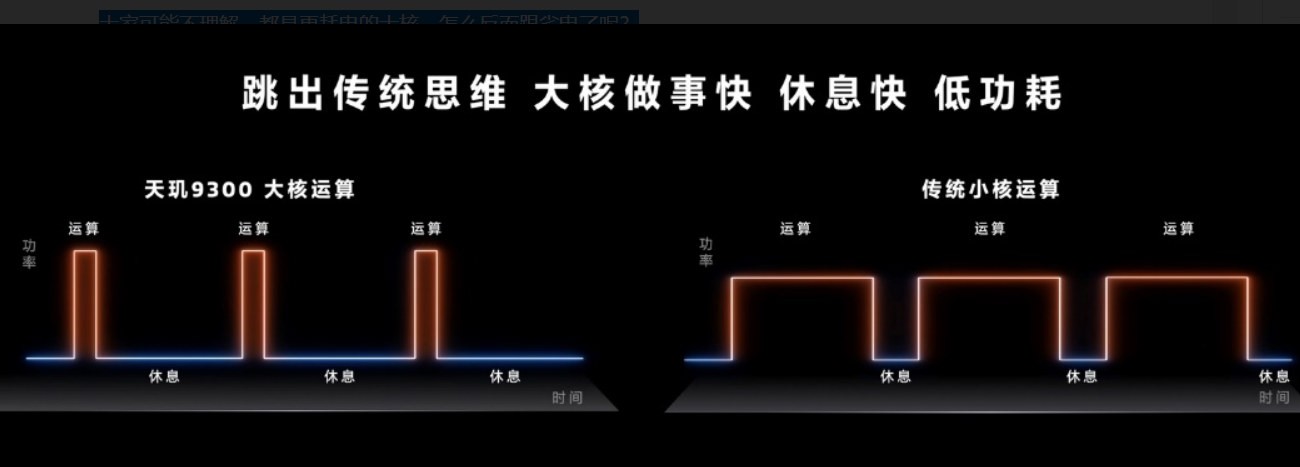
大家可能不理解,都是更耗电的大核,怎么反而跟省电了呢?
其实很简单,比如执行同样一个任务,大核心相比小核心在单位时间内多耗电50%,但只需1/3的时间就可以完成,总体下来大核心耗费的电量反而更少,自然能效更高。
一、开启全大核新时代:性能好能效高
每逢年底,旗舰级移动平台都会百花齐放、争奇斗艳,今年更加精彩。
前脚,三星Exynos 2400、高通骁龙8 Gen3竞相登场。
现在,联发科的天玑9300更是上演压轴大戏,带来了颠覆性的变革——“全大核”。
大家知道,自从Arm提出big.LITTLE大小核设计理念后,近些年的手机处理器,尤其是旗舰型号,一直都坚持这种思路,即便加入所谓超大核后,也只是一种延伸拓展,本质并没与变化。
大小核的初衷是分工协作,大核主抓繁重任务,小核提高能效。
这种设计在前些年表现是相当完美的,特别是配合不断进步的制程工艺,可以很好地兼顾性能、能效。
但是一方面,手机应用场景、工作负载一直在不断变化,对于处理器性能的需求也并非一成不变,大小核的体系逐渐无法适应时代的演进,特别是小核心往往变得力不从心。
另一方面,制程工艺进步的难度越来越大,提升的效果却越来越不明显,再加上Arm对于小核架构一直意兴阑珊,提升极小,这就造成原本应该省电的小核变得不再那么省电,有时候反而成为拖累。
其实在天玑9000系列诞生之前,联发科就在深入思考未来之路怎么走,尤其是如何破解随着性能提高、功耗也越来越高的难题,前前后后花了三年多的时间,才有了如今的天玑9300。
天玑9300跳出传统架构设计思维,改为全大核架构,包括四个最高主频为3.25GHz的Cortex-X4超大核心,以及四个主频2.0GHz的Cortex-A720大核心。
如此设计的好处是多方面的:
一是平行运算能力大幅提升,对比上代天玑9200峰值性能提升了多达40%,无论执行单个繁重任务还是多个并行任务,效率都得以大幅提升,而且同时将功耗降低了33%,兼顾续航。
大家可能不理解,都是更耗电的大核,怎么反而跟省电了呢?
其实很简单,比如执行同样一个任务,大核心相比小核心在单位时间内多耗电50%,但只需1/3的时间就可以完成,总体下来大核心耗费的电量反而更少,自然能效更高。
二是全面应用乱序执行内核,从而提升应用执行效率,减少卡顿的发生。
传统小核心架构都是顺序执行,也就是面对多个指令,要按照顺序依次执行,哪怕突然有紧急任务,也必须等待当前指令执行完成后再说。
这种设计好处是省电,坏处就是效率偏低。
乱序执行则是高性能架构的标配,可以灵活地根据执行、负载优先级,并行多个执行。
三是多线程并行应用启动。
在全大核架构下,系统会自动识别并优先执行重要任务,减少等待的时间。
同时,性能更强的大核心拥有更强的计算性能,特别是资源拥挤的时候可以更从容地满足需求,哪怕正在执行其他任务,也可以快速启动新的应用。
以下是现场演示的原神最高画质和微信视频通话同时运行,目测满帧的游戏和通话体验:
四是可以轻松双开高负载应用。
无论超大核还是大核,都可以满足高负载应用的需求,同时打开两个也不会出现资源不足。
比如以60帧极高画质玩《原神》的同时,还可以进行微信视频通话,30分钟的时间里可以全程满帧,实测相比传统大小核架构平均帧率提升15.5%,平均功耗则降低12.3%。
当然,也可以同时游戏和直播,都不耽误。
对于大屏手机、折叠屏手机来说,多应用并行、高负载应用双开尤为实用,可以充分利用屏幕空间。
那么,全大核架构相比传统的大小核架构,是否需要系统和应用单独优化调配呢?
对此,联发科解释说,CPU有着很好的通用性,而全大核架构的内部区别更小,所以基本不存在这样的问题,而且联发科一直都在内部做好持续的性能调校、优化,在外部做好好客户、生态系统的合作调优。
此外,联发科还在与Google持续合作,从上游源头的Android系统、AOSP项目上做好支持,减轻开发者负担,实现用户的无感化。
在联发科看来,随着应用环境的变化、半导体工艺的艰难,全大核架构将是未来的大趋势,相信行业都会往这个方向走,甚至是苹果也会如此,联发科就是勇敢地在引领这个潮流。
二、登上端侧AI新高度:330亿参数大模型轻松搞定
天玑9300集成了全新的第七代APU 790 AI处理器,行业首款搭载了硬件生成式AI引擎,同时集成性能核心、通用核心,全链路针对生成式AI进行优化,整数、浮点运算性能都提升了2倍,功耗则降低了45%。
天玑9300目前已经成功运行330亿参数的大模型,相比骁龙8 Gen3 100亿遥遥领先,而且与vivo深度合作,实现了70亿参数大语言模型端侧落地、130亿参数大语言模型端侧运行。
天玑9300重点解决了端侧AI三大痛点:内存限制、生成速度偏慢、大模型应用类型受限。
针对手机内存容量限制,天玑9300支持内存硬件压缩技术NeuroPilot Compression,结合大语言模型的INT4混合精度量化,将大模型的内存占用大幅减少了61%。
比如它还支持了330亿参数大模型,原本需要至少13GB内存,因此对于16GB内存手机来说就完全不够用。
而在联发科的调教下,只需5GB就够了,加上Android系统本身占用4GB、APP应用保活需要6GB,甚至还能富余1GB的自由空间。
针对生成速度问题,天玑9300深度适配Transformer模型,优化Softmax+LayerNorm算子,处理速度提升多达8倍。
此外,天玑9300支持行业速度最快的LPDDR5T 9600Mbps内存,可提供77GB/s带宽,保证AI运算无瓶颈。
正是这些设计,使得天玑9300 70亿参数大模型生成速度达到了每秒20 Tokens,Stable Diffusion 1.5文生图速度可以做到1秒之内。
针对大模型数量在端侧受限的问题,天玑9300拥有行业领先的LoRA(低秩自适应)融合,并首次搭载生成式AI端侧“技能扩充”技术NeuroPilot Fusioin,为基础大模型提供更全面的端侧能力,实现多样化的本地内容生成。
以上提及的很多技术和优化,都是联发科NeuroPilot AI开发平台的一部分,可以为开发者提供端侧生成式AI落地的一站式资源,以及诸多案例分享。
目前,联发科端侧生成式AI已有20多个合作伙伴,包括谷歌、Meta、百度、百川、抖音、快手、虎牙、爱奇艺、美图秀秀等等。
三、GPU等其他技术:光追迈上新台阶
除了全大核CPU、高性能AI,227亿晶体管堆叠的天玑9300在其他各个方面也是诚意满满,都处于行业领先水平,再简单回顾下:
天玑9300集成了全新一代的旗舰级GPU Immortalis-G720,拥有12个核心,相比上代11核心的Immortalis-G715峰值性能提升了46%,相当于以往两代的进步,同等性能下功耗降低40%。
在前代引入硬件光线追踪、可变刷新率的基础上,天玑9300搭载了第二代硬件光追引擎,光追游戏可以稳定跑到60FPS,还有游戏主机级别的全局光照技术。
此外,联发科特有的MAGT游戏自适应调控技术,现已升级为星速引擎,让·硬件状态、游戏需求之间双方“奔赴”,互相了解,不仅与游戏广泛合作,还将拓展到更多类型的应用。
目前,已有50多款游戏加入天玑光追生态,覆盖Unreal、Unity、Messiah三大引擎,涵盖八种不同类型。
Imagiq 990旗舰级ISP,集成AI语义分割视频引擎,支持16层图像语义分割,实时逐帧优化画面色彩、纹理、噪点、亮度等,景深和光斑双引擎升级,集成OIS光学防抖专用核心,支持全像素对焦叠加2倍无损变焦。
MiraVisioin 990显示单元,支持180Hz WQHD、120Hz 4K显示输出,集成旗舰智能电视级别的AI景深画质引擎,结合APU AI性能可实时监测主要物体与背景图像,动态调整主要物体的对比度、锐度、色彩,增强立体感。
音频降噪支持3个麦克风,具备全向高动态收音能力、噪音分离技术。
无线连接支持Wi-Fi 7,理论峰值速度6.5Gbps,搭配独家Wi-Fi 7增强技术MediaTek Xtra Range 2.0,室内覆盖范围可达4.5米,另有最多3个蓝牙天线,以及双路蓝牙闪连技术。
5G基带支持Sub-6GHz四载波聚合、多制式双卡双通,UltraSave 3.0技术可大幅降低5G通信功耗,5G/AI融合可支持情景感知功能。
四、跑分:全方位力压竞品
说一千道一万,硬件设计再好,技术特性再多,也要看性能发挥如何。
虽然说跑分不代表一切,但无论何时,跑分都是产品档次最基础和最直接的体现。
这一次,我们提前拿到了联发科提供的天玑9300工程样机,进行了多轮跑分测试,下边的对比成绩来自小米14系列首发的骁龙8 Gen3,均取最好成绩。
工程样机非常方正、厚实,比常规手机大了好几圈,主要是因为在外侧又包裹了辅助结构,方便测试调试,也有利于强化散热。
安兔兔跑分213.5万分,达到了新高,相比骁龙8 Gen3领先超过1万分。事实上体质好的机器上甚至能跑到215万分以上。
细看子项目,可以看到CPU、GPU都明显领先对手,内存、UX略低一些,但毕竟是工程样机。
GeekBench 6.2单核成绩2209、多核成绩7587,体质好的机器多核能跑到7700分以上。
对比骁龙8 Gen3,单核性能领先大约1%,基本持平,多核性能则领先超过6%,全大核表现不错。
GPU性能上天玑9300彻底爆发了,霸王龙高达887FPS,曼哈顿3.0、3.1分别达到497FPS、337FPS,2K分辨率/High的阿兹特克废墟OpenGL、Vulkan分别抛出94FPS、99FPS。
对比骁龙8 Gen3,以上各个项目分别领先大约72%、39%、31%、29%、29%。
霸王龙项目已经有些老旧,这里忽略不计,也可以看出天玑9300 GPU的优势达到了惊人的20-40%。
考虑到移动GPU都已经加入第二代光线追踪,我们特意测试了最新的Basemark GPUScore In-Vitro。
它的光追渲染场景占比约有25-30%,相比于另一个光追测试工具3DMark Solar Bay 10-15%的比例高得多,更能体现高负载光追游戏的实际表现。
实测天玑9300拿到了4714分,对比骁龙8 Gen3领先大约28%,这和GFXBench测试结果基本相符,证明发哥这次在GPU上确实威猛,一向被调侃为“买GPU送CPU”的高通要压力山大了。
再看看实际游戏表现,首先是必不可少的《原神》,60帧模式,极高画质,在虚拟城跑15分钟,实际渲染分辨率为1800×810。
结果平均帧率达59.7FPS,曲线十分稳定,平均功耗则是4.63W。
然后是《崩坏:星穹铁道》,60帧模式,最高画质,在星槎海跑15分钟,实际渲染分辨率为1680×756。
结果平均帧率达到58.8FPS(体质好的机器上可以超过59FPS),也相当稳定,而平均功耗为5.13W。
AI当然也是如今手机SoC性能不可或缺的一部分,但因为各家架构设计不尽相同,也缺乏行业统一标准的测试工具,其实不太好横向对比。
AI Benchmark中跑出了3145分(工程机终端得分),这个项目刷新了记录,天玑9300成为了目前的AI性能第一。
在AI Benchmark官网上,天玑9300获得了AI算力(芯片)第一名。
当然,AI还要看生成式应用,实际体验文生图不到1秒钟就可以完成,文生文也可以快速输出相当有质量的诗词。
总的来说,天玑9300作为联发科的新一代顶级旗舰,带来了更新的全大核CPU设计、全链路优化的AI、强大的GPU、综合平衡的平台技术与体验,又一次让“发哥”站在了巅峰,也正式吹响了新一代旗舰移动平台终极大战的号角。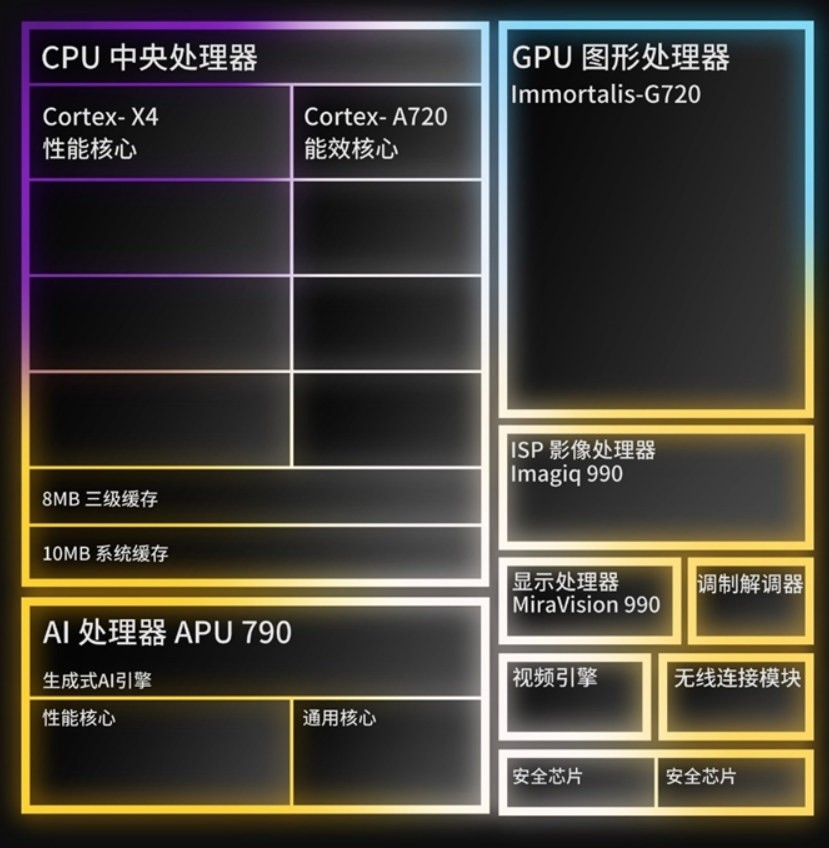
从首发测试跑分来看,天玑9300的综合性能、CPU性能都略微超过了骁龙8 Gen3,GPU性能远远胜出,实际游戏体验相当稳,生成式AI也能迅速得到想要的结果,总体甚至有些超出我们的预期。
11月13日,vivo X100将首发搭载天玑9300发布,现在就看手机终端的表现了!
相信随着vivo X100系列的全球首发和天玑9300的更多应用,高端市场将再次迎来一股新浪潮,推动整个行业向前发展。