
We briefly introduced how to use the speech studio tool for custom speech recognition and custom speech synthesis. The process of these two functions must prepare data in advance, and then use these data to train to meet the requirements. Models, and then use these models in combination with SDK or REST API for business processing. Today we continue to introduce another powerful tool for audio content creation (Audio Content Creation). Using this tool, you can easily make visual adjustments to speech synthesis, such as adjusting tone, intonation, voice level, mood, and so on. It can be widely used in audiobooks, news broadcasts, chatbots, etc. In addition to using the custom model provided by Microsoft, you can use the model you have trained yourself. At the same time, Microsoft also provides voice models in many scenarios, which can be used directly and then fine-tuned.
Another thing to note is that our tool is based on the SSML markup language, so after you use the tool to create the content you need, you can export the content into an SSML file, which can be used in more scenarios.
Let’s use this tool today to create an example of telling a story to a child. I hope everyone likes it.
Use Speech Studio’s audio creation to tell your baby a story
Prepare a story book
First of all, we need to prepare a story book. Let's use "Dudiu Xiong's Into the City" as the blueprint.
Then the content of the story book is formed into text, you can type it by hand, or you can use image recognition technology to recognize all the text, it's up to you. After we were ready, we started to use speech studio to create
Use Speech studio to create a new project
Before using speech studio, you need to have an Azure subscription and create a speech service with a standard pricing tier. Then log in to the Speech Studio tool through the address: https://speech.microsoft.com (Azure Globa) or Https://speech.azure.cn (Azure China), and select audio content creation on the Portal
我们前面简要的介绍了如何使用speech studio这个工具进行自定义的语音识别和自定义语音合成的强大的功能,这个两个功能的过程都是必须先期准备数据,然后使用这些数据训练出符合要求的模型,然后使用这些模型结合SDK或者REST API进行业务处理,我们今天继续介绍另外一个强大的工具有声内容创作(Audio Content Creation)。使用该工具你可以很方便的对语音合成进行可视化的调整,例如调整语气,语调,声音高低,情绪等等。可以广泛的用在有声读物,新闻广播,聊天机器人等等场景,除了可以使用微软提供的自定义的模型,你可以使用自己前面自己训练出来模型。同时微软也提供很多场景下的语音模型,可以直接使用,然后进行一定的微调。
另外需要注意的是我们这个工具是基于SSML标记语言的,所以你在使用该工具创建好需要的内容之后,你完全可以将该内容导出成SSML文件,从而应用在更多的场景下。
我们今天来使用该工具创建一个给孩子讲故事的实例,希望大家喜欢。
使用Speech Studio的有声创作给宝宝讲故事
准备故事书
首先我们需要准备一本故事书,我们这里就以《丢丢熊进城记》为蓝本吧。
然后将故事的书的内容形成文字,您可以手打,也可以使用图片识别技术将所有的文字识别出来,都随你。准备好了之后, 我们开始使用speech studio进行创作了
使用Speech studio创建新项目
在使用speech studio之前,你需要有Azure订阅,并且创建了标准定价层的Speech服务。然后通过地址:https://speech.microsoft.com(Azure Globa)或者Https://speech.azure.cn(Azure中国)登录到Speech Studio工具中,在Portal上选择有声内容创作, 如下图:
创建新故事
然后选择新建文件, 如下图:
新建文件之后的界面如下图:
将新建的文件保存为一个新的名字,我们这里是:丢丢熊进城记:
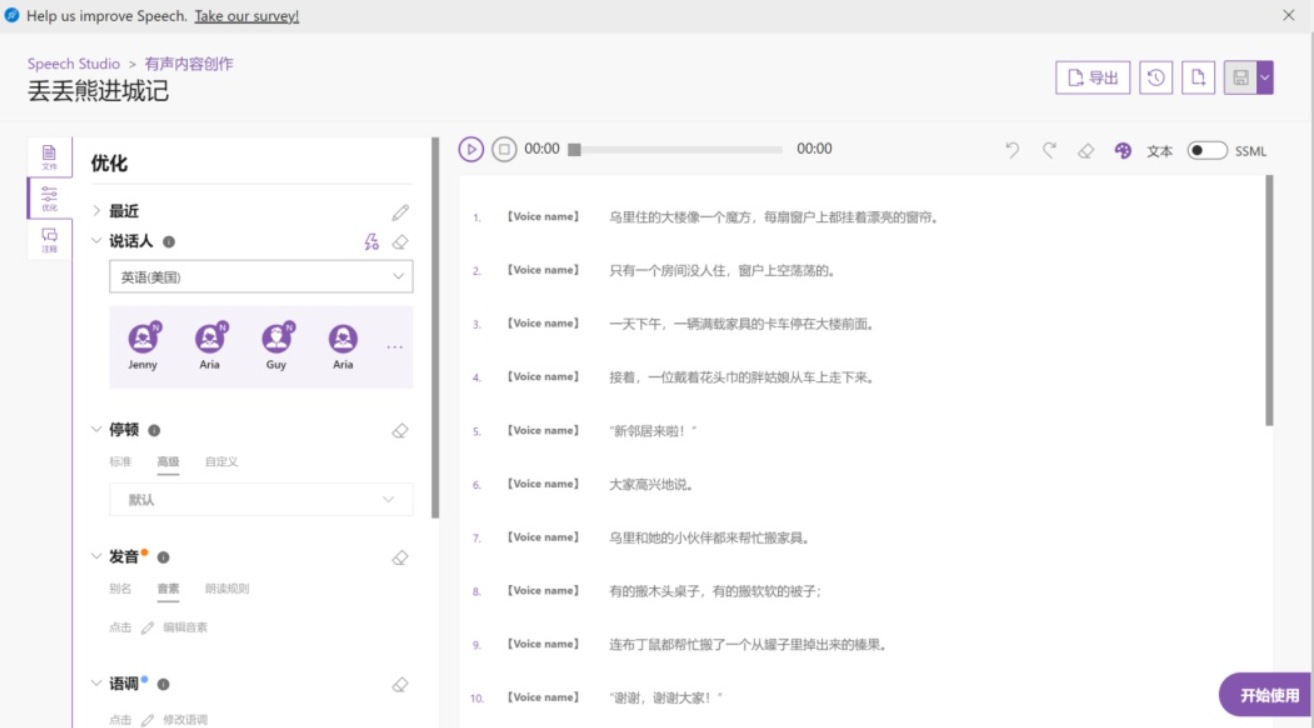
然后把我们准备好的文字,按照读故事的进度,将所有的文本都拆成句子,输入到文本框中,如下图:
选择讲故事的语音模型
准备好基本的数据之后,我们需要给给这个故事定义一些角色,首先故事里有丢丢熊,有布丁鼠,有大家,有讲故事的人,我们可以对每一句语音使用不同的语音模型,从而给出不一样的风格,先选择语言:
注意是每一句每一句的设定,所以先选择第一句,然后在左侧选择为中文简体,默认会列出如下的可以选择的模型:
你可以点击左侧的语音模型的... 弹出更多的选择:
可以对这些模型一一浏览,选择自己喜欢的,因为我们这里是讲故事,因此我们选择”晓呦"
然后我们看一下左侧的可以调整的功能有哪些:
从这里大家可以看到不同的模型有不同的设置选项,例如如果选择了默默,你可以选择角色,以及语音,音素,语调,音高等等。
在这里你可以发挥您的想象,进行不同的设置,如下图是我简单设置的例子:
公众号: AzureDeveloper, 敬请关注
摘自 https://zhuanlan.zhihu.com/p/379735118