
WordPress是一款非常流行的开源内容管理系统,它可以帮助用户轻松地创建和管理自己的网站。而通过wp-json接口,用户可以方便地抓取WordPress网站的数据。本文将介绍如何使用wp-json接口抓取WordPress网站数据。
什么是wp-json接口?
wp-json接口是WordPress提供的一种API,它可以让开发人员和用户轻松地访问和处理WordPress网站的数据。这个API被称为REST API,它支持多种HTTP请求方法(如GET、POST、PUT、DELETE等),并返回JSON格式的数据。
如何使用wp-json接口抓取WordPress网站数据?
1. 查找wp-json接口
首先,要使用wp-json接口抓取WordPress网站数据,需要找到wp-json接口的URL。wp-json接口的URL格式是:
```
https://your-website.com/wp-json/
```
请将“your-website.com”替换为您的WordPress网站的域名或IP地址。
2. 测试wp-json接口
在浏览器中输入wp-json接口的URL,例如:
```
https://your-website.com/wp-json/
```
如果您可以看到以下JSON格式的响应,那么您已经成功地访问了wp-json接口:
```
{
"namespace": "",
"routes": {
"\/": {
"namespace": "",
"methods": [
"GET"
],
"endpoints": [
{
"methods": [
"GET"
],
"args": {
"context": {
"default": "view",
"required": false,
"enum": [
"view",
"embed",
"edit"
],
"description": "Scope under which the request is made; determines fields present in response."
}
},
"url": "\/wp\/v2\/"
},
...
],
"endpoints_by_methods": {
"GET": [
{
"methods": [
"GET"
],
"args": {
"context": {
"default": "view",
"required": false,
"enum": [
"view",
"embed",
"edit"
],
"description": "Scope under which the request is made; determines fields present in response."
}
},
"url": "\/wp\/v2\/"
},
...
]
}
},
...
},
"authentication": [],
"nonced_routes": {}
}
```
这个JSON响应包含了wp-json接口的命名空间、路由、认证方法等信息。
3. 抓取WordPress网站数据
一旦您成功访问了wp-json接口,您就可以抓取WordPress网站的数据。wp-json接口支持多种路由和端点,例如:
- `/wp/v2/posts`:获取所有文章的列表
- `/wp/v2/posts/{id}`:获取特定文章的详细信息
- `/wp/v2/pages`:获取所有页面的列表
- `/wp/v2/pages/{id}`:获取特定页面的详细信息
- `/wp/v2/comments`:获取所有评论的列表
- `/wp/v2/comments/{id}`:获取特定评论的详细信息
- `/wp/v2/users`:获取所有用户的列表
- `/wp/v2/users/{id}`:获取特定用户的详细信息
例如,要获取所有文章的列表,请访问:
```
https://your-website.com/wp-json/wp/v2/posts
```
这将返回一个JSON格式的响应,其中包含所有文章的列表。
4. 过滤和排序数据
wp-json接口还支持过滤和排序数据。例如,要获取所有标题包含“WordPress”关键字的文章的列表,请访问:
```
https://your-website.com/wp-json/wp/v2/posts?search=WordPress
```
这将返回所有标题包含“WordPress”关键字的文章的列表。
要按发布日期排序文章,请访问:
```
https://your-website.com/wp-json/wp/v2/posts?orderby=date
```
这将返回按发布日期排序的文章的列表。
5. 限制数据的返回数量
wp-json接口还支持限制数据的返回数量。例如,要限制返回的文章数量为10篇,请访问:
```
https://your-website.com/wp-json/wp/v2/posts?per_page=10
```
这将返回10篇文章的列表。
6. 认证和授权
wp-json接口还支持认证和授权。您可以使用OAuth、Cookie、HTTP Basic Authentication等方法进行认证和授权。这可以确保只有授权用户才能访问和处理WordPress网站的数据。
结论
通过wp-json接口,用户可以方便地抓取WordPress网站的数据,并进行过滤、排序和限制返回数量等操作。这使得wp-json接口成为WordPress网站数据处理的理想选择。如果您想了解更多关于wp-json接口的信息,请访问WordPress官方文档。
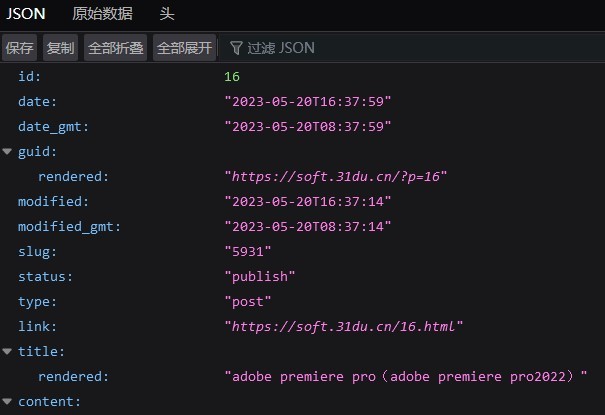
WordPress网站一般会有开放的接口来获取网站元数据
参考:https://developer.wordpress.org/rest-api/reference/posts/
例如这个样例网站:https://soft.31du.cn/
获取他们博客列表接口为:
https://soft.31du.cn/wp-json/wp/v2/posts/
一般读接口都是不保护的,你直接浏览器打开就能访问到。
我们一般抓取一个WordPress网站,只需要抓取他的posts、categories、tags即可。
我这里简单写了个Python脚本来执行需要数据的爬取
你可能会注意到pull第三个参数是一个数值,这个数值是要抓取的数据的页数,这个页数从哪里获取呢?
你直接用浏览器打开它对应接口数据,看他的返回头里面有个数值,他的key是x-wp-totalpages。
WordPress返回头里面会塞入接口对应数据的数量。