
人工智能权威榜C-Eval榜单含金量到底有多高 随着ChatGPT等大模型的涌现,中国的AI研发者日益意识到与国际巨头的差距,对于中文大模型的权威评测标准变得更加迫切。为满足这一需求,上海交通大学与爱丁堡大学联手打造C-Eval榜单,旨在为中文语言模型提供综合性的评估工具。本文将深入剖析C-Eval的构建背景、涵盖的学科范围以及其在AI领域的权威性和参考价值。
ChatGPT 的出现,使越来越多的中国研发者意识到与国际领先水平的差距,尽管中文大模型的研发如火如荼层出不穷,但具有权威性的中文大语言模型认定基准却比较少。为此,上海交通大学和爱丁堡大学合作研发,构建了面向中文语言模型的综合性考试评估套件C-Eval,用来辅助开发者们进行中文大模型的开发,也就是我们时常听到的C-Eval榜单。
那么C-Eval榜单究竟有什么意义,对于上下游的企业又有什么样的参考作用,我们接下来就一项一项的进行解读。
C-Eval榜单是什么?
C-Eval榜单,全称C-Eval全球大模型综合性考试测试榜,是由清华大学、上海交通大学和爱丁堡大学合作构建的中文语言模型综合性考试评估套件。
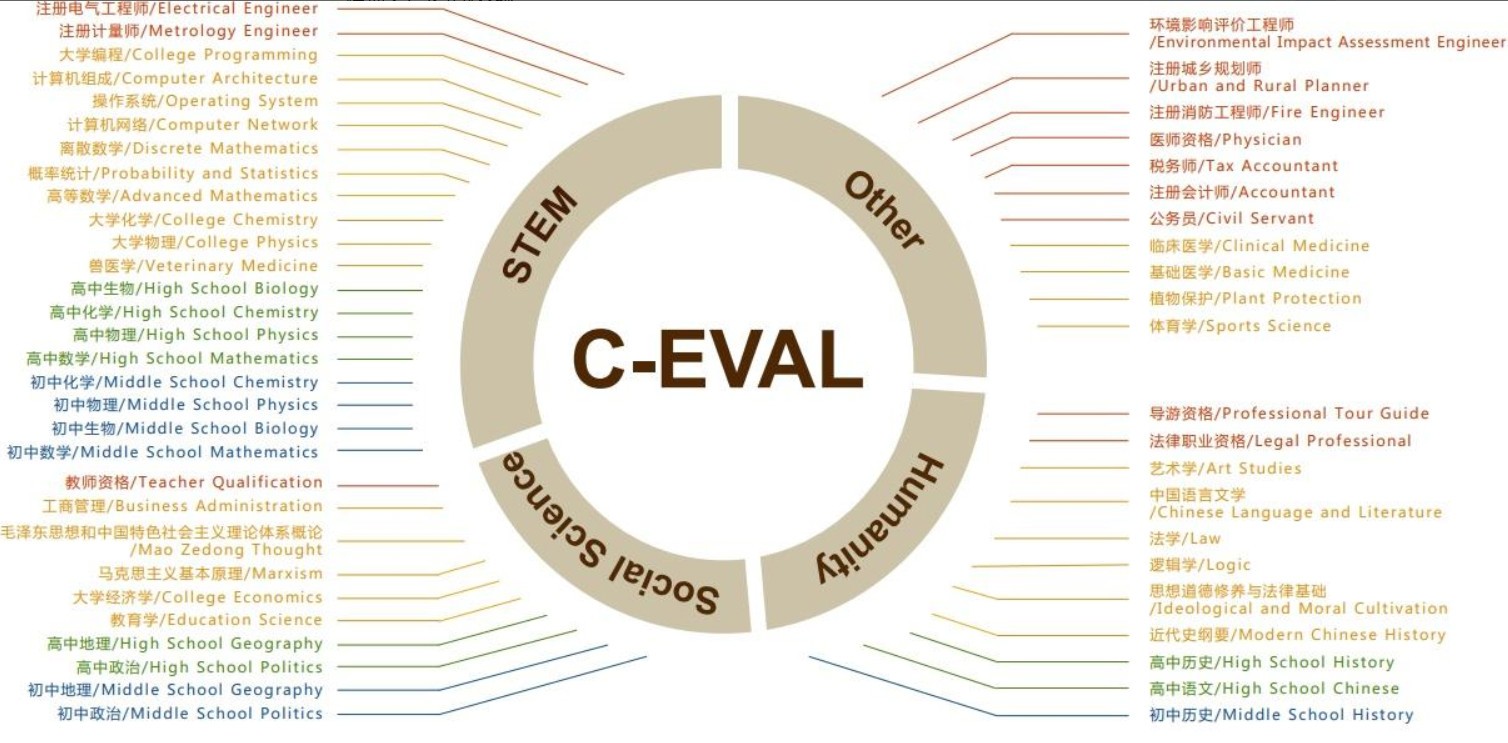
C-Eval语言大模型的学科分类
该套件覆盖人文、社科、理工、其他专业四个大方向,包括52个学科,涵盖微积分、线性代数等多个知识领域。共有13948道中文知识和推理型题目,难度分为中学、本科、研究生、职业等四个考试级别,能够更加全面的对模型的语言处理能力进行评估,对中文社区语言大模型的研发有着很好的参考价值。
C-Eval全球大模型综合性考试测试榜含金量有多高?
C-EVAL为清华大学、上海交通大学和爱丁堡大学合作研发,作为中文大模型的基准,与在mmlu、agieval并列为目前对模型潜力判断最具权威性的大模型榜单。C-Eval测试题目为选择题,据开发团队介绍,严格的预设机制杜绝了混入训练集的可能,因此在正常考察模型潜力上的公正性和全面性较高,在开发者中也有很高的权威性,能够帮助开发者快速分析判断模型的能力。
截至8月初最新一期榜单
进入C-Eval榜单代表着提交模型的语言判断能力以达到行业领先的水平。
但C-Eval榜单并非是判断模型优劣的绝对标准,C-Eval并不能完全杜绝研发团队作弊提高排名的可能,预设的机制更多是对模型爬虫能力的限制而非人员,在开发团队前期发布的文章中,也列出了两种套用模型主要的作弊机制,并呼吁模型开发人员选择困难但正确的道路,不要为了冲击榜单而走捷径。
此外,C-Eval主要参与自主参与的方式,暂未囊括行业全部团队,部分商业公司以及专业团队都尚未参与到榜单的交流中。
C-Eval全球大模型综合性考试测试榜有什么参考价值?
C-Eval的主要作用是学术价值,用于开发交流使用,帮助开发者进行模型迭代,鼓励更多的专业开发者参与并构建更好的中文社区研发生态,推动中文社区整体发展。#夏天生活图鉴#
C-Eval排名并不具有绝对的商业判断价值,作为辅助开发者判断迭代的工具榜单,C-Eval每期都会有相对的变化,而商业价值判断应从多维度出发,包括开发团队的综合能力、模型的实用性等等。诚如C-Eval开发团队呼吁的那样,希望研发团队科学的使用C-Eval,不要过多的将名利带入研发段,这样才能最大化利用C-Eval造福中文社区。
C-Eval榜单作为一项重要的学术评估工具,主要为AI开发者提供模型迭代的参考指导,并鼓励更多的专业研发者参与到中文社区的建设中。然而,其排名并不意味着绝对的商业价值,开发者和企业需从多角度综合评判模型的实际应用价值。希望各研发团队能够科学、理性地利用C-Eval,真正推动中文AI模型的发展,不为名利所困,为中文社区创造更多的价值。